
日本語に特化した『生成AI』を試作 NICT
国立研究開発法人情報通信研究機構(NICT、徳田英幸理事長)はこのほど、NICTイノベーションセンター(日本橋)(東京都中央区)で、「大規模言語モデル(生成AI)の開発について」記者説明会を開催した。NICTは、ユニバーサルコミュニケーション研究所データ駆動知能システム研究センター(DIRECT)において、独自に収集した350GBの日本語ウェブテキストのみを用いて400億パラメータの生成系の大規模言語モデルを開発したと発表した。今回の開発を通し、事前学習用テキストの整形、フィルタリング、大規模計算基盤を用いた事前学習等、生成系の大規模言語モデル開発における多くの知見を得た。現在は、さらに大規模な1790億パラメータの生成系大規模言語モデル(米OpenAI社のGPT―3と同等規模)の学習を実施中で、また、学習用テキストの大規模化にも取り組んでいる。今後、共同研究等を通して民間企業、国研、大学等と協力して、日本語の大規模言語モデルの研究開発や利活用に取り組む考えだ。 NICTが開発した日本語に特化した生成系大規模言語モデルについて開発を主導したNICTフェローの鳥澤健太郎氏が説明した。 まずNICTの自然言語処理技術のここ数年の成果を述べた。 「NICTは自然言語処理の研究を長年に亘って行ってきている。最初は大量のウェブページを元に質問を入れると大量の回答を検索する『WISDOM X』(ウィズダム・エックス)を開発して試験公開している。2021年の3月に深層学習版『BERT』という大規模言語モデルを使ったバージョンを試験公開している。この技術を災害向けに〝同調〟する形でツイッター上の災害情報を分析するシステム『DISAANA/D―SUMM』(ディサーナ/ディーサム)を試験公開している。民間企業へ技術移転した。次にLINEを使って被災者や自治体職員から、災害情報を集めて分析集約する防災チャットボット『SOCDA』(ソクダ)。これは民間企業との共同研究でこれも開発して、民間企業がビジネスを開始している。また『WISDOM X』の技術を最近は、高齢者の健康状態を対話でチェックするシステムであるマルチモーダル音声対話システム『MICSUS』(ミクサス)を開発して、民間企業が商用化を検討している」と話した。(全文は7月10日付け1面に掲載)
投稿者プロフィール
最新の投稿
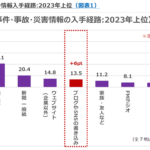 放送コンテンツ2023.09.01ビデオリサーチ 災害情報入手経路の7割が地上波民放テレビ
放送コンテンツ2023.09.01ビデオリサーチ 災害情報入手経路の7割が地上波民放テレビ 行政2023.09.016年度総務省所管予算概算要求 『光ファイバの整備の推進』で66億円
行政2023.09.016年度総務省所管予算概算要求 『光ファイバの整備の推進』で66億円- Unknown2023.08.31【特集】令和5年「防災の日」総務省総合通信局別施設整備等の展望
 放送コンテンツ2023.08.31朝日放送グループ、ぼうさいこくたい2023 にワークショップを出展
放送コンテンツ2023.08.31朝日放送グループ、ぼうさいこくたい2023 にワークショップを出展