
3分の音声データから自分の声を合成する技術を開発 KDDI総研
KDDI総合研究所(埼玉県ふじみ野市、中村元・代表取締役所長)は、3分程度の少量の音声データから、その人の声質に似た音声を合成する「高効率声質再現音声合成技術」を開発したと発表した。この技術により音声収録にかかる時間を大幅に軽減でき、独自の声質を使った音声対話システムやチャットシステムなど、これまでにない新しいコミュニケーション体験が容易に実現できる。 多様かつ大量の情報にあふれている現代において、画面を見たり操作したりする方法での情報活用には限界があり、AIスピーカーや対話ロボットを中心とした音声インタラクションでの情報活用手段が注目されている。 KDDI総合研究所は、これまでに、スマートフォンやIoT・組み込み向けマイコンボード単体で省メモリかつ軽量に動作する日本語テキスト音声合成ソフトウエア「N2」を提供するなど、情報出力手段として重要となる音声合成技術を誰でも簡単に使えるようにする技術の研究開発を進めてきた。しかし、あらかじめ用意した声質以外での音声合成は容易ではなく、独自の声質を使いたいニーズへの対応が課題となっていた。 今回、KDDI総合研究所は3分程度の少量の音声データからでもその人の声質に似た音声を合成できる「高効率声質再現音声合成技術」を開発した。この技術は基となる音声合成方式にDNN-HSMM音声合成方式を採用することで、合成音声品質の低下を抑えつつ音声の特徴を表すパラメーターの数を削減し、さらに独自のDNN適応技術を組み合わせることで、短時間の音声から高効率にその声質を再現する音声合成を実現した。 DNNーHSMM音声合成方式は、HSMM音声合成(HSMM、隠れセミマルコフモデル)におけるHSMMパラメーターを、深層ニューラルネットワーク(DNN)でモデル化することで高品質な音声を合成する方式。 この手法を検証するため、数十名の話者による100時間以上の音声で学習した汎用的なDNNを新規の約3分の音声で適応し、その声質を再現した合成音声を作成した。この手順で作成した10声質、各5文の合成音声に対して、基となった自然音声との比較を11名の判定者により行ったところ、94%の音声で、似た声質の音声が合成できていると過半数の判定者により判定された。 今後、他のサービスから同技術を容易に利用可能にするためのプラットフォーム化の検討を進める。また、どこでも簡単に録音作業ができたり、より短時間の音声でも音声合成ができたりすることや、合成音声が適切に利用されることを確保する機能など、この技術を安全で使いやすい技術にしていくための研究開発を進める。 さらに、本技術の基盤であるDNNーHSMM音声合成方式の処理量が他の深層学習に基づく方式よりも小さいことを生かし、日本語テキスト音声合成ソフトウエア「N2」と統合した、PCやスマートフォン、ロボット上でスタンドアローン動作する音声合成システムの開発を進める。
この記事を書いた記者
最新の投稿
 実録・戦後放送史2024.09.02連載にあたって
実録・戦後放送史2024.09.02連載にあたって- 筆心2024.09.022024年8月26日(第7712号)
 放送ルネサンス2024.09.02放送100年特別企画 「放送ルネサンス」第1回
放送ルネサンス2024.09.02放送100年特別企画 「放送ルネサンス」第1回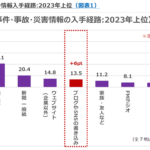 放送2023.09.01ビデオリサーチ 災害情報入手経路の7割が地上波民放テレビ
放送2023.09.01ビデオリサーチ 災害情報入手経路の7割が地上波民放テレビ